![[Python] 파이썬으로 웹 스크래핑하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fcw741Q%2FbtrF9SVfWzI%2FAAAAAAAAAAAAAAAAAAAAAG3SAzZ1BDbS7Ygegu4fACBlxqnFoU2MQ5DVSXO8h-6Y%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3Dp%252FwP6%252B83yQXzqYg4ua2DZBGxHPA%253D)
스파르타 코딩클럽 웹개발 종합반 강의를 수강하며 공부한 웹스크래핑 내용을 정리해 보았다.
웹 크롤링 vs 웹 스크래핑
웹 크롤링은 url을 탐색해 반복적으로 링크를 찾아 가져오는 과정이다. 웹 스크래핑은 특정 웹페이지의 데이터를 추출하는 것이다. 정보를 수집한다는 공통점이 있지만, 크롤링의 경우 특정 웹페이지를 타겟으로 하지 않고, 또한 데이터 중복 방지를 위해 색인을 남기기 때문에, 웹 인덱싱이라고도 한다.
필요 패키지 설치
가상 환경 폴더에 필요 패키지를 설치해준다.
# requests 패키지 : HTTP 요청을 위한 라이브러리이다.
pip install requests
# BeautifulSoup : requests를 통해 가져온 html을 파싱하여 의미있는 데이터를 추출한다.
pip install bs4
# 추가로 VS code 에서 사용할 수 있는 파이썬 code formatter를 설치해주었다.
pip install -U autopep8requests 와 BeautifulSoup을 활용한 스크래핑
기본 코드 프레임은 아래와 같다.
import requests # requests 모듈 임포트
from bs4 import BeautifulSoup # bs4 모듈 내 BeautifulSoup 클래스 임포트
# 타겟 url
url = 'https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829'
# 웹 서버에 get 요청
data = requests.get(url)
# 응답코드가 200(정상)이 아닐 시 예외 발생
data.raise_for_status()
# 응답 객체의 text 속성, 내장 html.parser를 사용해 BeautifulSoup 객체화
soup = BeautifulSoup(data.text, 'html.parser')+ 웹스크래핑시 웹 서버가 가짜 로봇 클라이언트의 접근을 막기 위해 요청을 거부할 수 있는데, 이 때 우리가 사람이라는 것을 서버에 알려주기 위해서 사용자 에이전트(user agent) 정보를 요청과 함께 전달할 수 있다.
# 나의 user agent 정보가 담긴 headers 객체를 만든다.
headers = {'User-Agent': 'WhatIsMyBrowser.com에 접속해 여기에 들어갈 내용을 찾을 수 있다.'}
# url과 함께 headers를 전달하여 get 요청을 보낸다.
data = requests.get(url, headers=headers)WhatIsMyBrowser < 이 링크를 클릭해 user agent 정보를 확인할 수 있다.
BeatifulSoup 객체화 된 html에서 원하는 데이터는 다음과 같이 가져온다.
# copy selector를 통해 추출한 selector 정보
# #old_content > table > tbody > tr:nth-child(2) > td.title > div > a
# 모든 데이터가 공통으로 가진 부분을 .select로 전체 선택한다.
movies = soup.select('#old_content > table > tbody > tr')
# 그리고 반복문 내에서 필요한 부분의 selector를 select_one 메서드로 각각 지정하여 할당한다.
# .text 혹은 ['속성'] 으로 원하는 부분을 추출할 수 있다.
for movie in movies:
a = movie.select_one('td.title > div > a')
if a is not None:
title = a.text
rank = movie.select_one('td > img')['alt']
score = movie.select_one('td.point').text
doc = {
'rank': rank,
'title': title,
'score': score
}
select 메서드 대신 find 메서드를 이용해 태그로 추출하는 방법도 있다.
스크래핑 결과 DB 저장
위 코드에서 스크래핑한 결과를 출력하면 아래와 같다.

이런 데이터를 저장하고 활용할 수 있도록 DB 에 저장하고자 한다. 활용할 DB는 NoSQL DB 인 mongoDB 이다.
- NoSQL : Nol Only SQL 전통적인 관계형 데이터베이스보다 융통성 있는 데이터 모델을 사용해 유연한 대처가 가능하다.
mongoDB Atlas에서 계정을 생성해 mongoDB 클라우드 서비스를 이용할 수 있다.
db 연결을 위해 아래 패키지를 설치한다.
pip install pymongo dnspythonpymongo에서 활용할 수 있는 코드는 다음과 같다.
# 전체 검색
# 모든 users 콜렉션의 요소
# = 리스트(찾을 db.찾을 컬렉션.찾기({조건 1}, {조건 2 - db가 자동생성한 _id를 제외한 값}))
all_users = list(db.users.find({}, {'_id': False}))
for user in all_users:
print(user)
# 특정 조건 하나만 검색
user = db.users.find_one({'name': 'kenny'}, {'_id': False})
print(user)
# 수정
# 찾을 db.찾을 컬렉션.하나를 업데이트
# ({조건}, {앞 조건을 set 하라: {적용할 내용}})
db.users.update_one({'name': 'kenny'}, {'$set': {'age': 19}})
# 삭제
db.users.delete_one({'name': 'kenny'})전체 코드
from pymongo import MongoClient
import requests
from bs4 import BeautifulSoup
url = 'https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829'
headers = {'User-Agent': 'WhatIsMyBrowser.com에 접속해 여기에 들어갈 내용을 찾을 수 있다.'}
data = requests.get(url, headers=headers)
data.raise_for_status()
soup = BeautifulSoup(data.text, 'html.parser')
# DB 연결
client = MongoClient(
'mongoDB에서 connectYourApplication을 선택하면 입력 코드가 나온다.')
db = client.dbname
movies = soup.select(
'#old_content > table > tbody > tr')
for movie in movies:
a = movie.select_one('td.title > div > a')
if a is not None:
title = a.text
rank = movie.select_one('td > img')['alt']
score = movie.select_one('td.point').text
doc = {
'rank': rank,
'title': title,
'score': score
}
#db 에 collection-name으로 doc을 insert_one 한다.
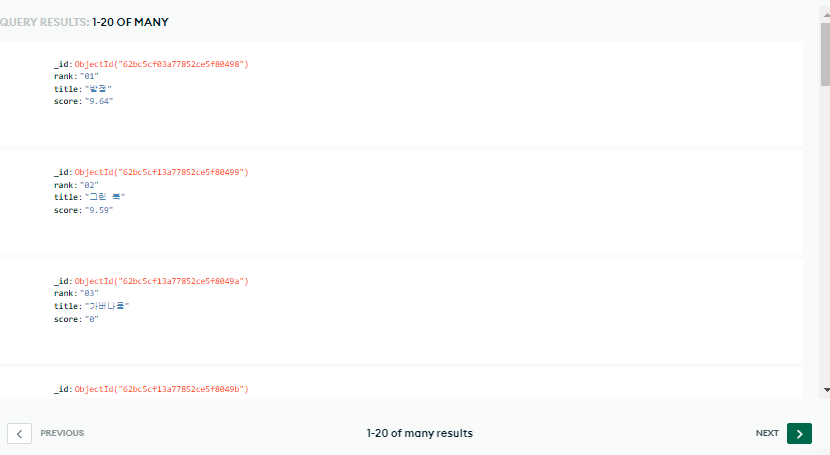
db.collection-name.insert_one(doc)이렇게 db에 저장을 마치면 mongoDB atlas에서 아래와 같이 확인할 수 있다.
참고 자료
'WEB' 카테고리의 다른 글
| [UI/ UX] 사용자 인터페이스(UI) , 사용자 경험(UX) 를 이해해보자 (0) | 2022.08.23 |
|---|---|
| [WEB] Postman - Weather API 사용해보기 (0) | 2022.08.08 |
| [WEB] REST API를 알아보자! (0) | 2022.08.05 |
| [NETWORK] 웹은 어떤 원리로 작동할까? : HTTP 간단 정리 (0) | 2022.08.04 |
| [jQuery] 제이쿼리를 활용한 Ajax get 요청 (0) | 2022.06.24 |